DSPy ist ein Python-Framework, das einen programmatischen Ansatz für das Prompting von LLMs bietet. Es ermöglicht eine strukturierte Definition von Eingaben und Ausgaben, wodurch eine konsistente Generierung von Modellausgaben erreicht wird.
Effiziente Steuerung von LLM-Eingaben und -Ausgaben
Das Framework kann mit beliebigen Sprachmodellen genutzt werden – sowohl mit lokal gehosteten LLMs als auch über API-Anbindungen wie GPT-4o. Über eine definierte Schnittstelle lassen sich Prompts als Funktionsaufrufe übergeben, wobei das LLM die generierte Antwort zurückliefert.
DSPy verwendet Signaturen, um das Modellverhalten präzise zu steuern. Diese legen Ein- und Ausgabewerte sowie die Verarbeitungslogik fest, wodurch eine bessere Kontrolle über das LLM ermöglicht wird.
Dieses Modell kann anschließend direkt per function aufgerufen werden. Ein Prompt wird übergeben, an das LLM geschickt und die generierte Antwort wird zurückgegeben.
Die Dauer der Generierung und die Qualität der Antwort hängt von dem Modell ab, ob es lokal gehostet ist und wie viele Parameter es enthält.
Signaturen
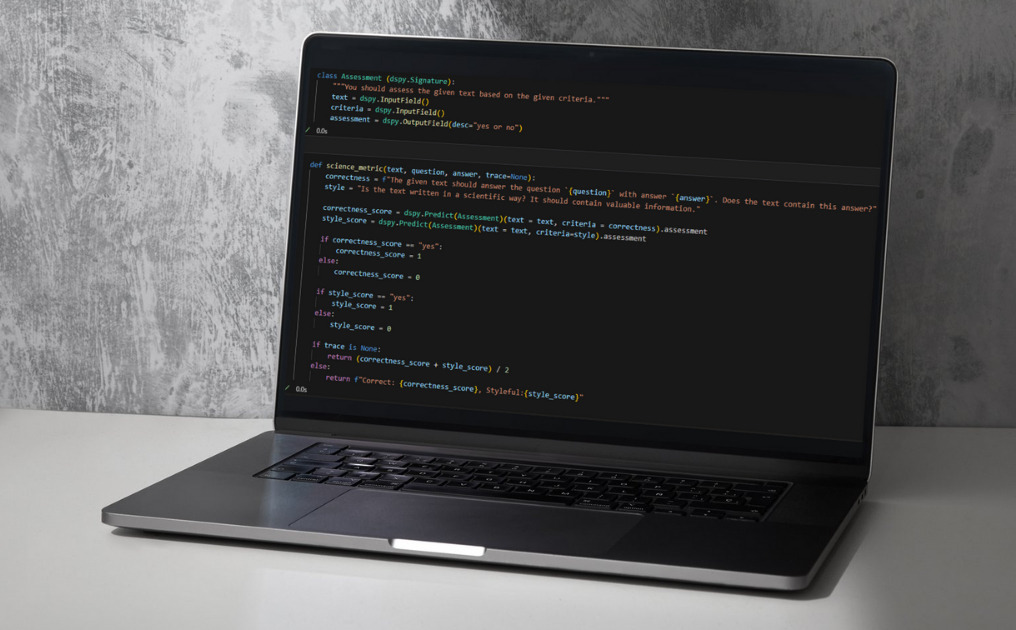
Die Funktionsweise von DSPy basiert auf sogenannten Signaturen. Diese dienen als Rahmen für Anweisungen, die dem Modell übergeben werden und nach denen es dann handelt. Eine Signatur legt die Ein- und Ausgabewerte sowie das allgemeine Verhalten des LLMs fest. In Klartextform (in einem Docstring) wird die Anweisung an das Modell hinterlegt. Der Inhalt des Kommentars wird dann vom Modell interpretiert und steuert dessen Verhalten.
Auf diese Weise lässt sich das Verhalten des Modells präzise steuern. Eine beliebige Anzahl an Ein- und Ausgabeparametern kann gewählt werden. Das Modell versteht, was die Namen der Eingaben bedeuten, und richtet sich danach, was im Kommentar dazu steht. So wird z. B. der Input eine Variable namens „context auch als solcher erkannt. Das Modell versteht, dass es sich beim hier eingegebenen Text um den Kontext der Eingaben handelt und verwendet diesen somit, um den restlichen Input besser einordnen zu können. Es ist auch möglich, die Variablen mit einer Beschreibung zu versehen. Dies er“möglicht z. B. eine Eingrenzung der möglichen Ausgabewerte und macht die Ausgabe dementsprechend präziser:
Um diese Signaturen an das LLM zu übergeben, werden sie in Module verpackt. DSPy stellt dafür verschiedene Arten von Modulen bereit:
Module
Predict
Dieses Modul gibt die Anweisungen zusammen mit den übergebenen Eingabewerten direkt an das LLM. Zurückgegeben wird ein „Predict“-Objekt, das einzig die definierten Ausgaben des LLMs enthält.
ChainOfThought
Dieses Modul generiert zuerst noch eine Zeile, in der es das LLM anweist, Stück für Stück zu denken und bei der Beantwortung des Prompts strukturiert vorzugehen. Dieses Vorgehen erhöht die Qualität der Ausgaben des Modells merklich. In dem zurückgegebenen „Predict“-Objekt findet sich neben den definierten Ausgaben auch die Zeile der zusätzlichen Instruktionen, die sogenannte Gedankenkette. Diese lässt sich als „inneren Monolog“ des Modells verstehen.
Metriken
DSPy beinhaltet sogenannte Metriken, die es ermöglichen, die Ausgaben von Modulen zu validieren und damit die Module selbst zu trainieren. Zum einen können Metriken alleine auf Code basieren, die Ausgaben auf Basis von festen Bedingungen als richtig oder falsch deklarieren. Zum anderen lassen sich LLMs innerhalb der Metriken nutzen, um zu entscheiden, ob die Ausgaben eines Moduls den Anforderungen entsprechen oder nicht. Dies ist z. B. beim Validieren von längeren Texten essenziell. Dies kann auch durch das Übergeben von Soll-Werten geschehen, die dann in den Prompt integriert werden können und somit in die Validierung mit einfließen können.
Optimizer
Optimizer werden verwendet, um die Qualität der Ausgaben eines Moduls zu verbessern. Dem Optimizer wird ein Modul und zugehörige Trainingsdaten gegeben. Diese werden Stück für Stück in das Modul gegeben, wobei die generierte Ausgabe in der Metrik validiert wird. Bei positivem Feedback wird das Trainingsdatum als Beispiel in das Modul integriert, sodass es bei zukünftigen Anfragen mitgeschickt werden kann. Dies ermöglicht Ausgaben, die näher am gewünschten Resultat liegen.
Wobei das eingegebene Trainingsset folgende Form hat:
Der Stand des Moduls nach der Optimierung lässt sich durch die Metrik mit dem Stand vor der Optimierung vergleichen. Dabei fällt auf, dass sich zum einen die Metrik verbessert, zum anderen eine Iteration jedoch deutlich länger dauert als vor der Optimierung, da die Beispiele mit dem Prompt zusätzlich an das Modell geschickt werden und das LLM dadurch deutlich mehr Informationen verarbeiten muss. In diesem Beispiel scheint eine Optimierung eher weniger sinnvoll, da die Aufgabe eine geringe Komplexität hat und die deutlich erhöhte Dauer der Anfrage gegenüber der leichten Qualitätssteigerung überwiegt.
Fazit
DSPy bietet eine strukturierte Möglichkeit, Sprachmodelle in Python zu integrieren. Der große Vorteil liegt in der präzisen Steuerung von Ein- und Ausgaben, wodurch zuverlässige und reproduzierbare Ergebnisse erzielt werden. Beispielsweise lassen sich mit DSPy einfache „True“- oder „False“-Antworten sicherstellen, die direkt im Python-Code weiterverarbeitet werden können.
Darüber hinaus ermöglichen die Metriken eine kontinuierliche Validierung der Modellausgaben. Falls erforderlich, können diese dynamisch angepasst und optimiert werden. Dadurch bietet DSPy nicht nur eine programmatische Lösung für das Prompting, sondern auch eine Möglichkeit zur Qualitätssicherung bei der Nutzung von LLMs.
Mit diesem Ansatz könnte DSPy zukünftig noch stärker in Workflows zur Automatisierung und Optimierung von LLM-gestützten Anwendungen integriert werden.
Der Beitrag DSPy: Das Python-Framework für strukturiertes LLM-Prompting erschien zuerst auf Business -Software- und IT-Blog – Wir gestalten digitale Wertschöpfung.